According to the World Health Organization (WHO), air pollution is the biggest environmental risk to health in the European Union (EU) causing each year about 400 000 premature deaths, and hundreds of billions of euro in health-related external costs [1]. Air pollution occurs when gases, dust particles and smoke are released into the atmosphere, making it harmful to humans, infrastructure and the environment. Particulate matter, nitrogen dioxide and ground level ozone are the air pollutants responsible for most of these early deaths.
We call smog any combination of air pollution, with or without humidity. The term smog (from smoke and fog) was created in early 1900s by the British researcher and doctor H.A. Des Voeux who conducted a research on after effects of air pollution problems in Glasgow and Edinburgh in autumn 1909, resulting in 1000 deaths [9].
The history of the problem of smelly smoke produced by forges, mines and other production facilities is very old. In 1273 the first known regulation was made in London regarding forbidden use of powdered coal. Since then there were many efforts put in place to control and improve air in big European and US cities. In 1775, Percival Pott, a well-known surgeon from London, described many cases of skin cancer of chimney sweeps and linked them to a contact with carbon black. In the industrial era, steam engines of steam locomotives, ships and factory machines became major pollution contributors. In 1888, a French professor Maximilien Ringelmann, invented the first way of pollution measurement, a few years later (1906) the first electrical precipitator was made. In the 20th century, new sources of pollution became apparent – cars and planes. The air pollution and associated with it global warming are considered one of the most serious civilizational and environmental challenges of the contemporary world [9].
There are two dimensions of air pollution and smog – global and local. Globally, it affects global warming. Locally, it influences quality of life and health of people living in different areas.
In Poland, environmental awareness started growing slowly in the mid-1950s, but mainly in academia. While the western world put a lot of effort into diversification of energy sources with the main goal of reducing coal, in Poland coal still remains the mainstay of energy source [2]. In the public debate, the main arguments against coal usage reduction are the need of mining industry preservation and destitute society not being able to afford modern, low emission solutions. While the world was improving, many Polish regions and cities started leading in pollution rankings. The quality of life – mainly during autumn and winter months – dropped drastically. Ultimately, in the 1990s consistent monitoring programs were put in place and various improvement programs were introduced (with the main contribution of UE regulations and funds) [4]. Unfortunately, the change happens very slowly, mainly due to people's awareness of the problem growing slowly and the limited knowledge of how the improvement should be handled efficiently.
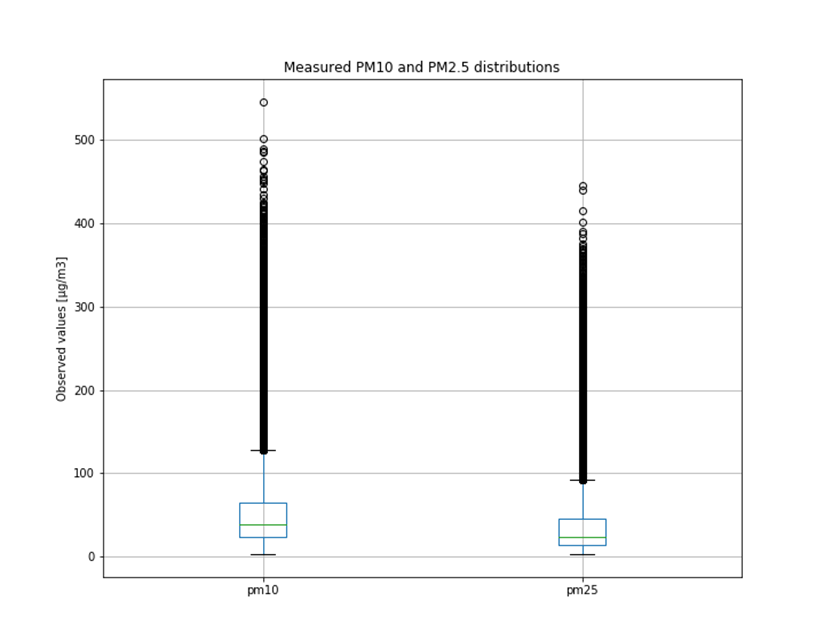
The WHO identifies particulate matter (PM), nitrogen dioxide (NO2), sulphur dioxide (SO2) and ground-level ozone (O3) as the main air pollutants that are most harmful to human health. The most dangerous of them are fine particles (PM2.5) which caused about 400 000 premature deaths of EU citizens in 2014 (and similarly in every consecutive year) [1].
Smog cannot be contained by authorities or environmental services alone. It can be only tamed by everyone, including ordinary people who need to understand how bad the smog is and act to replace cacoethes of burning garbage and (low-calorie) coal resulting in harmful substances in the air. It can be tamed by industry, another significant source of smog. In order to reduce it, we need to increase usage of ecological methods of heating but also in energy (power stations) and industrial production. Replacing old furnaces with modern ones with use of air cleaners could also help.
Air quality does not only depend on pollution emissions. It also depends on proximity to the source and altitude at which pollutants are released; meteorological conditions, including wind and heat; chemical transformations (reactions to sunlight, pollutant interactions); geographical conditions (topography). Air pollution emissions result mostly from human action (as stated before) but they can also result from forest fires, volcanic eruptions and wind erosion. Air pollution is natural but its extend in the modern world is not [9].
Smog can be very sneaky. It may have greater impact on children who, when become adult, may suffer from diseases related to chemical compounds cumulated in their bodies. That is another reason why it is so important to eliminate smog (long-term) and avoid open air activities (short-term) when smog concentration outside is too high.
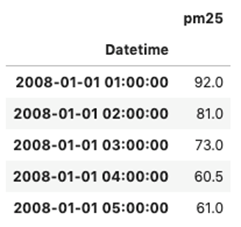
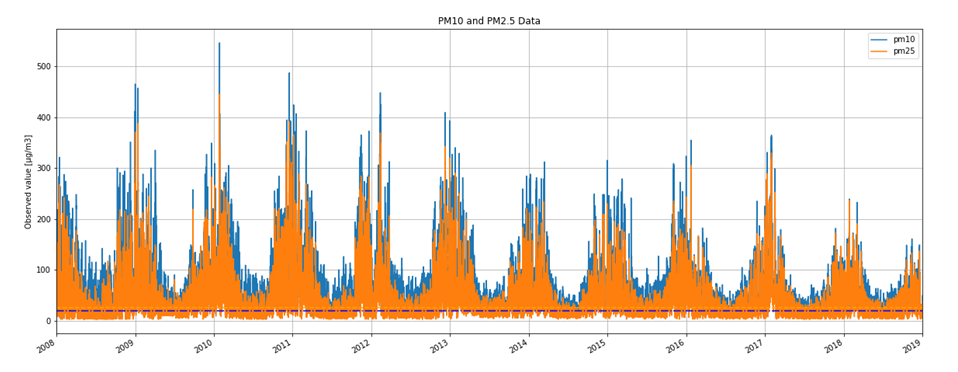
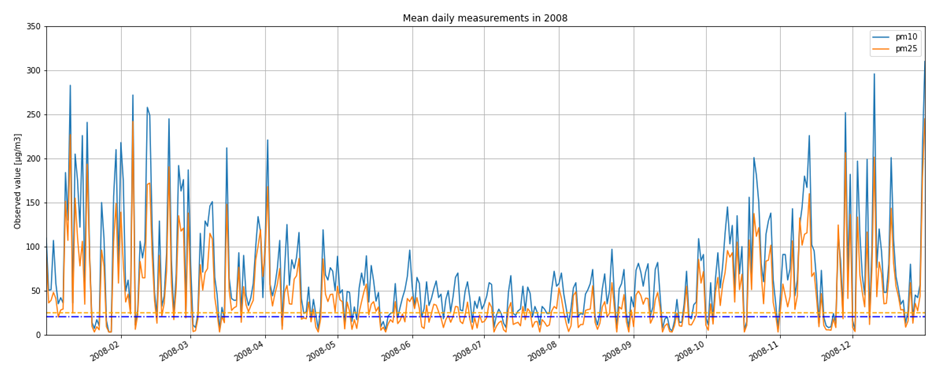
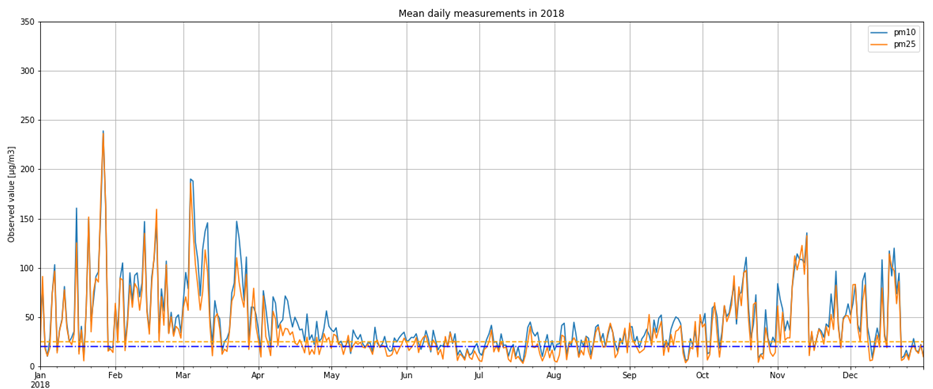
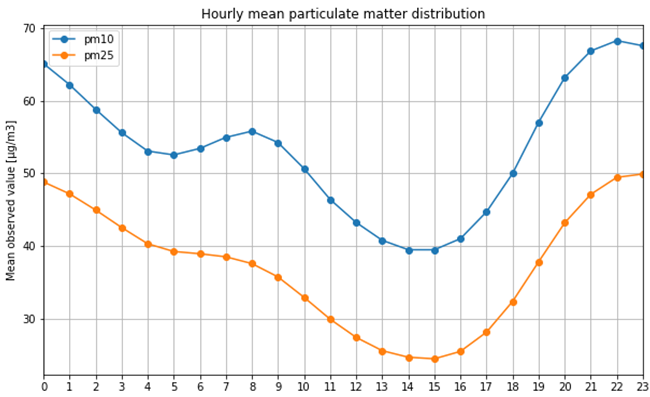
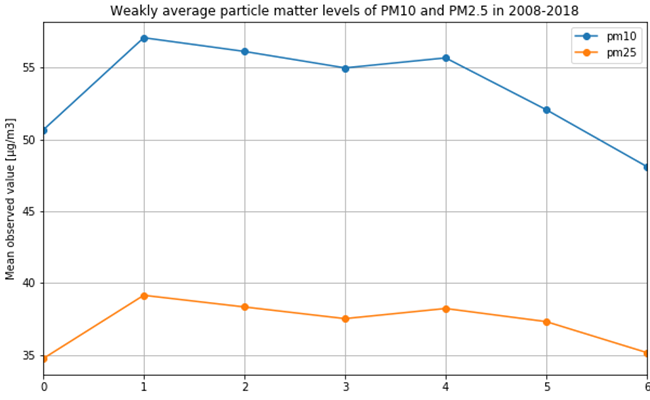
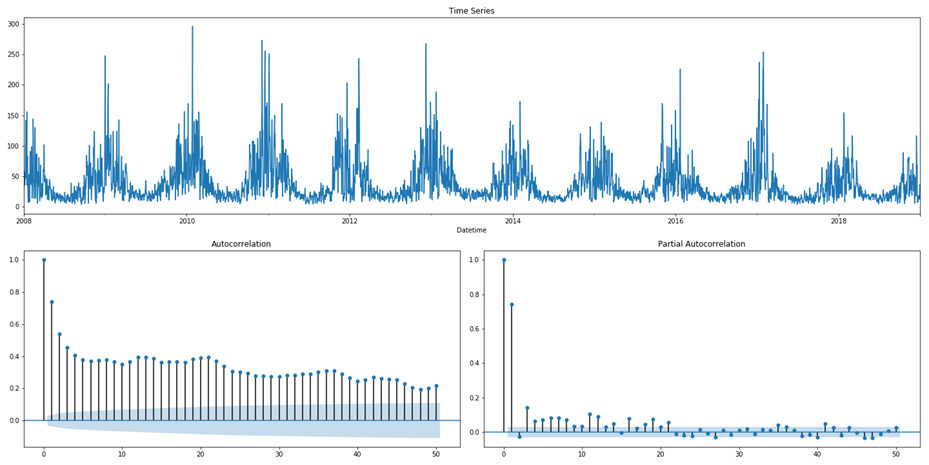
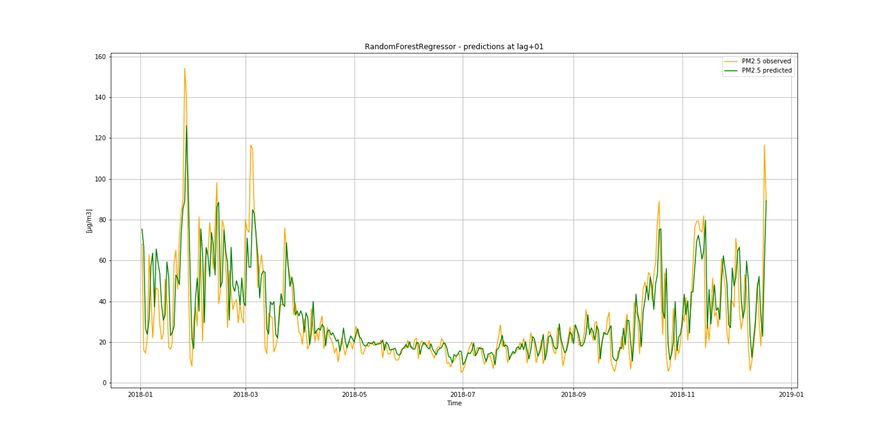
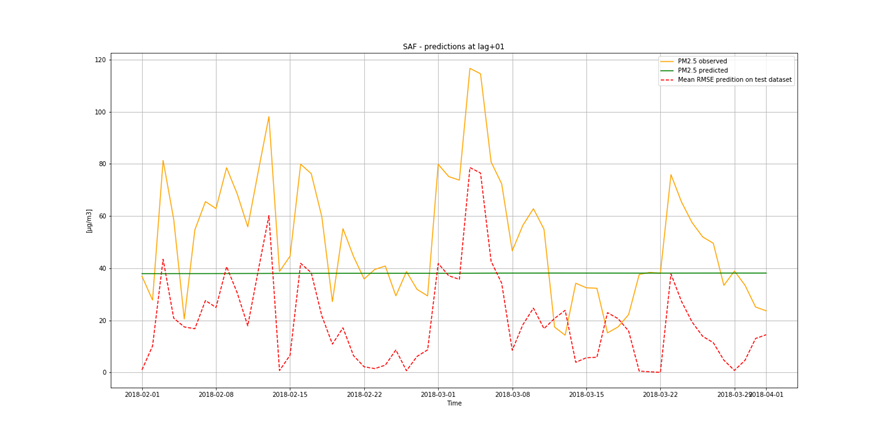
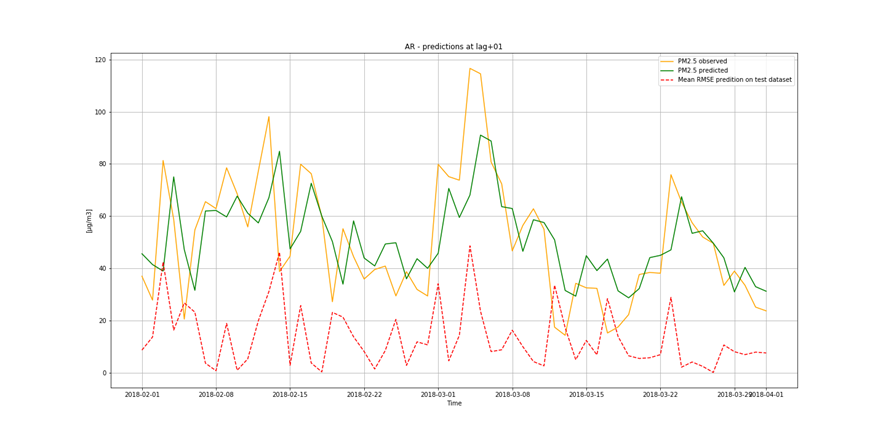
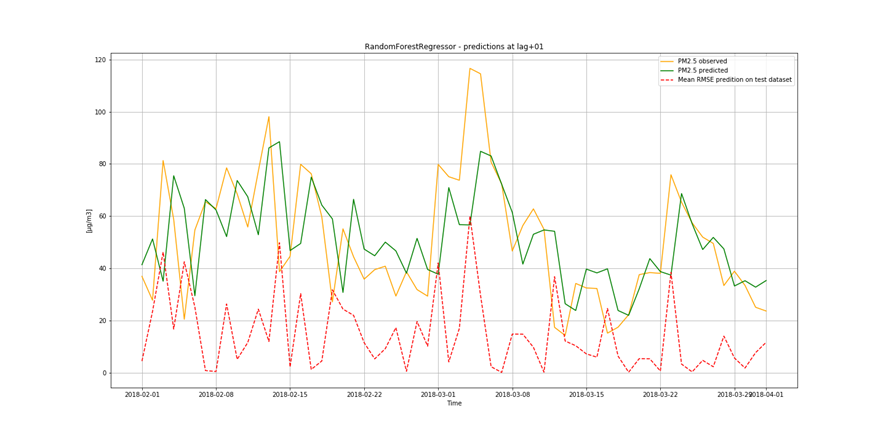
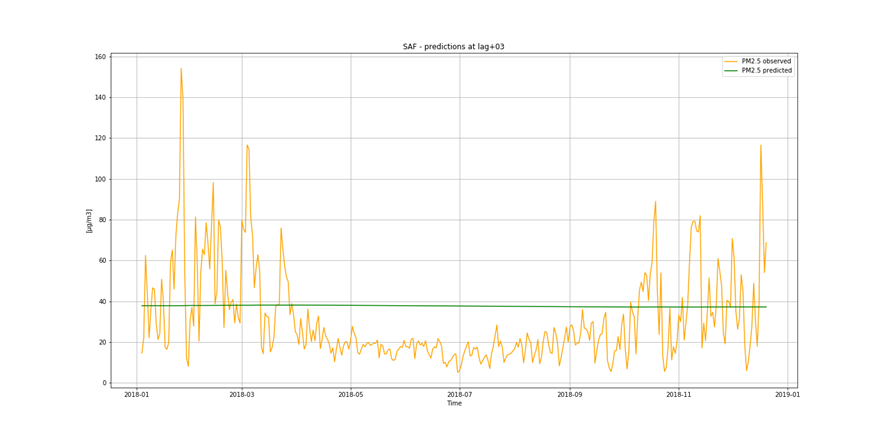
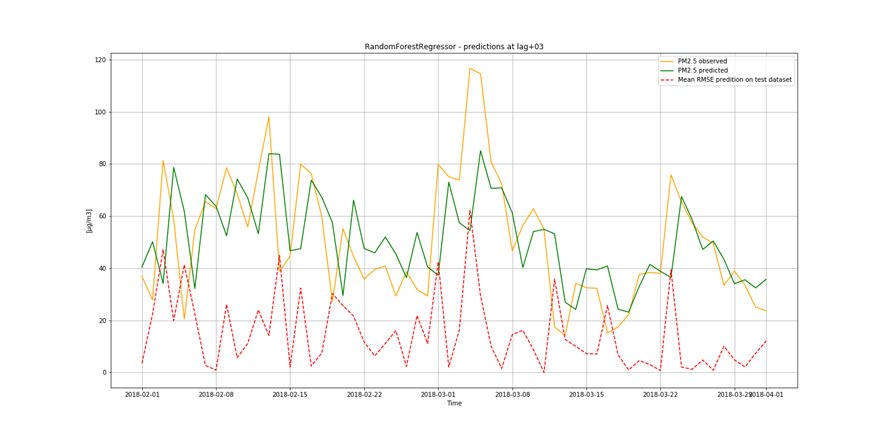
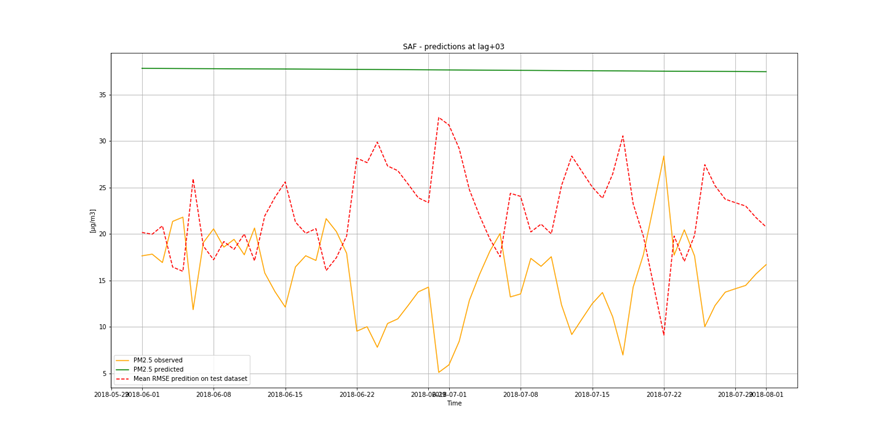
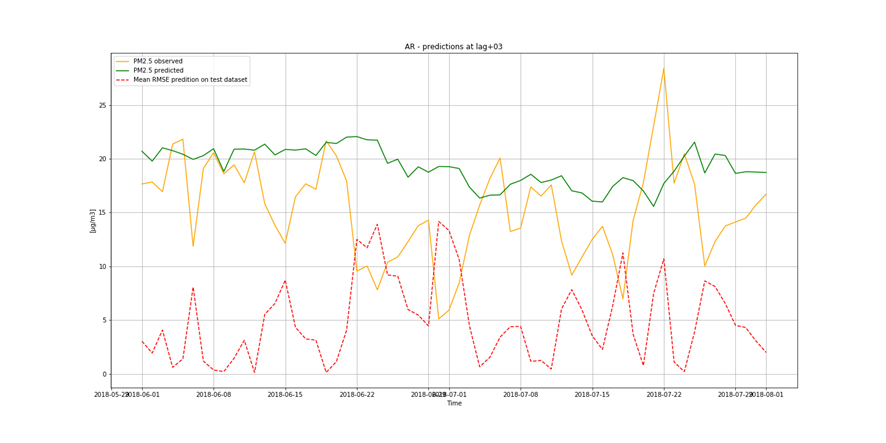
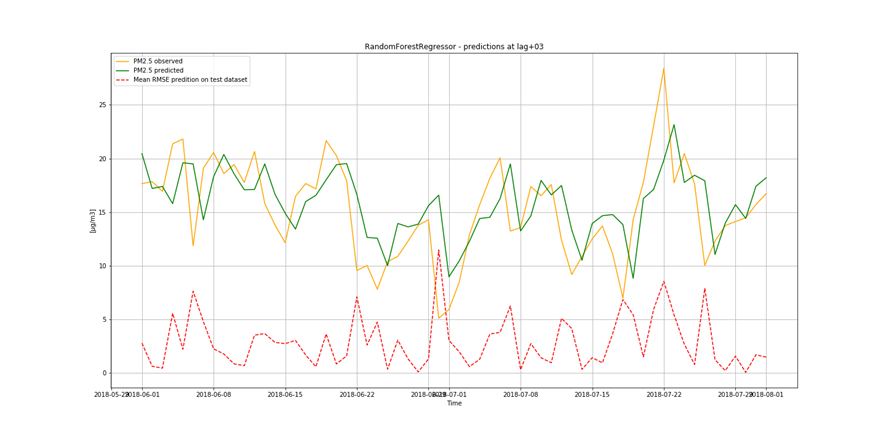
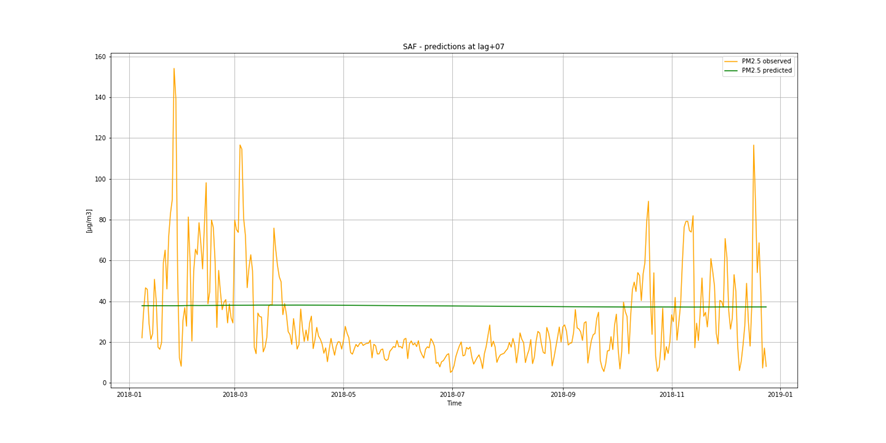
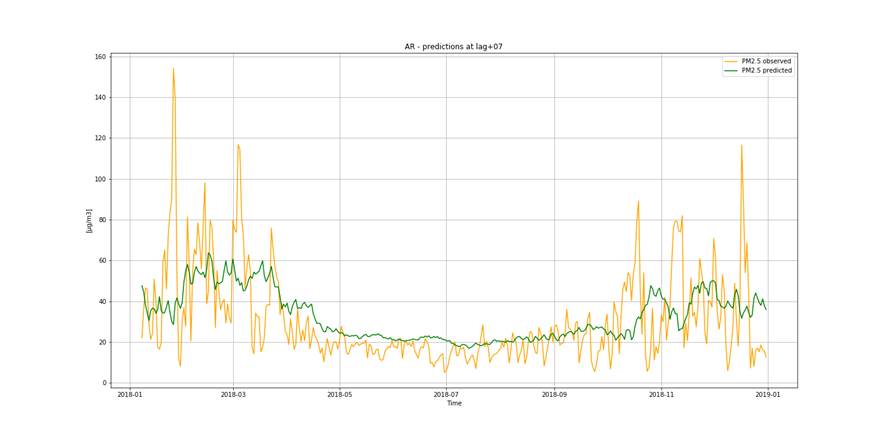
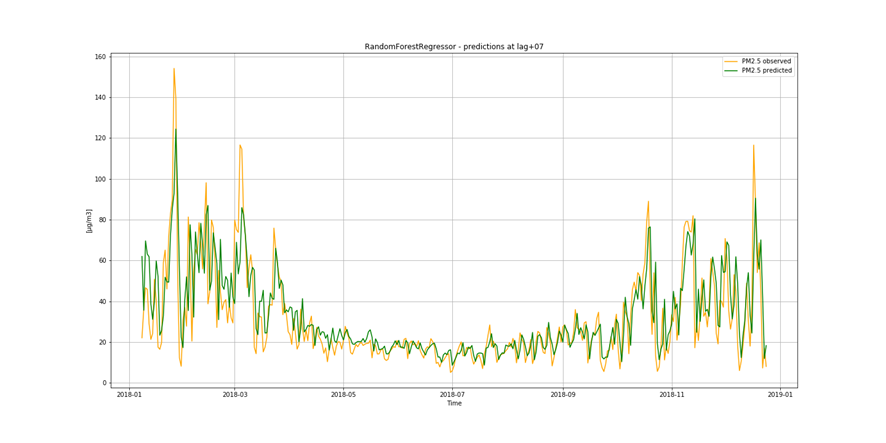
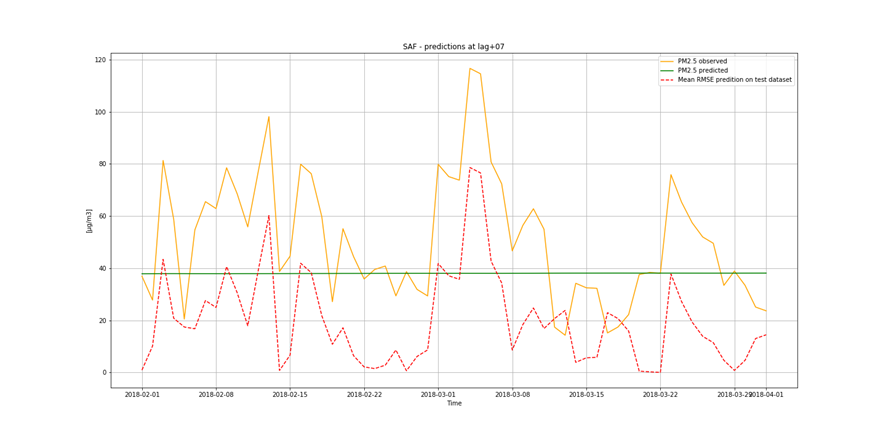
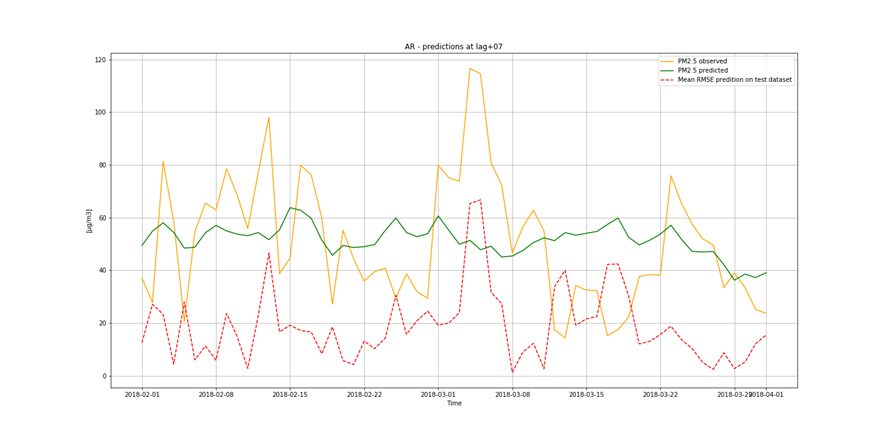
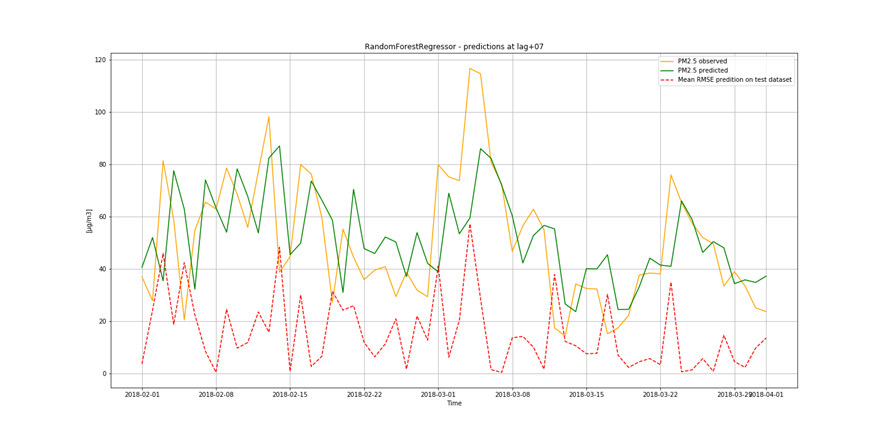
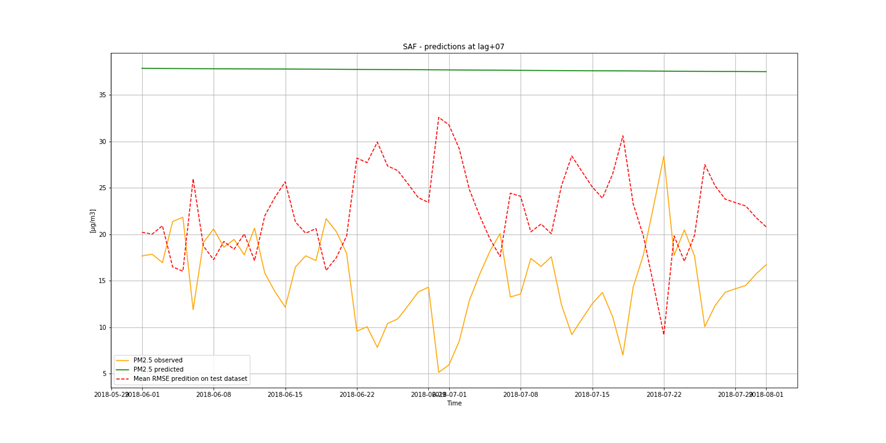
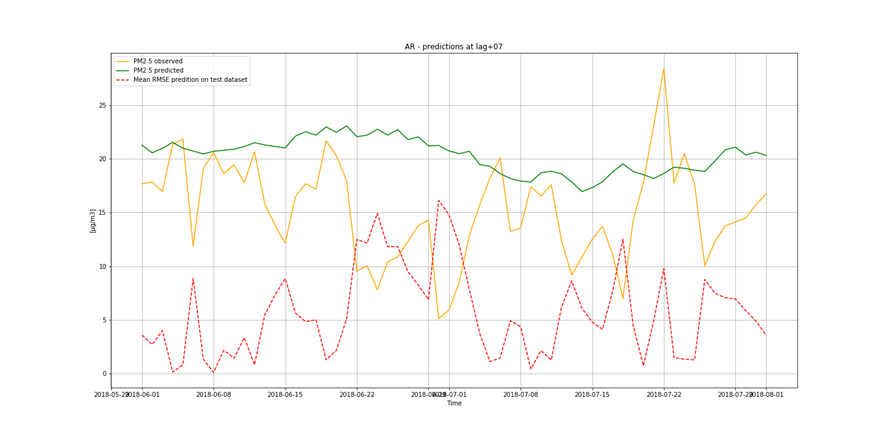
It is not only important to reduce air pollution but also to understand current air conditions around us to passively reduce its impact on our health by limiting our exposure. This is the main reason for the research described in this study – based on existing air pollution sensors' measurements (collected in the Kraków area, a high pollution hotspot). Kraków - my home city - struggles with very poor air quality, particularly during the winter season. Concentrations of particulate matter (PM10 and PM2.5) and benzo(a)pyrene are exceedingly high throughout the whole region.
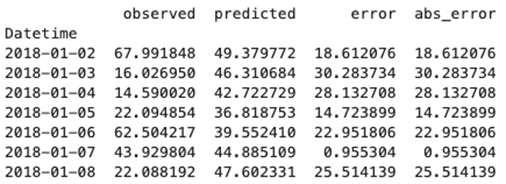
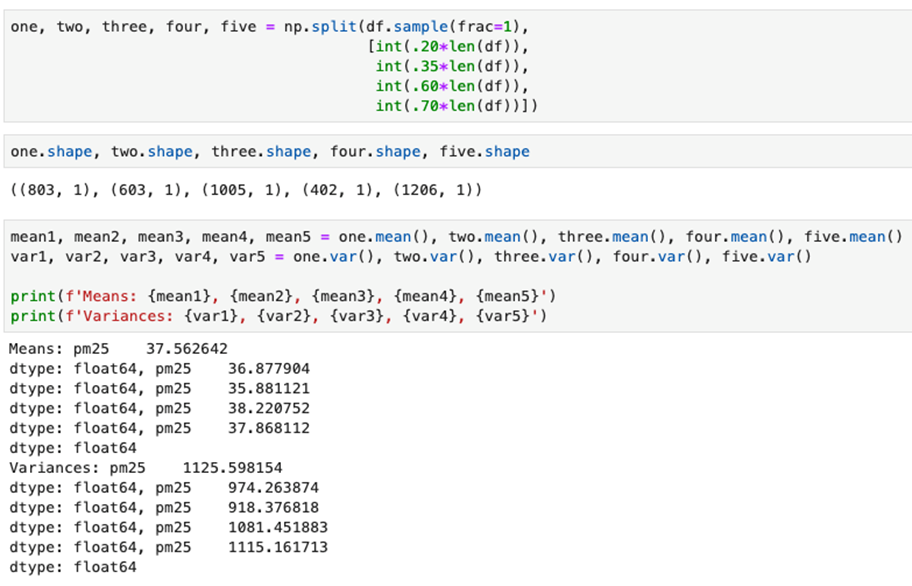
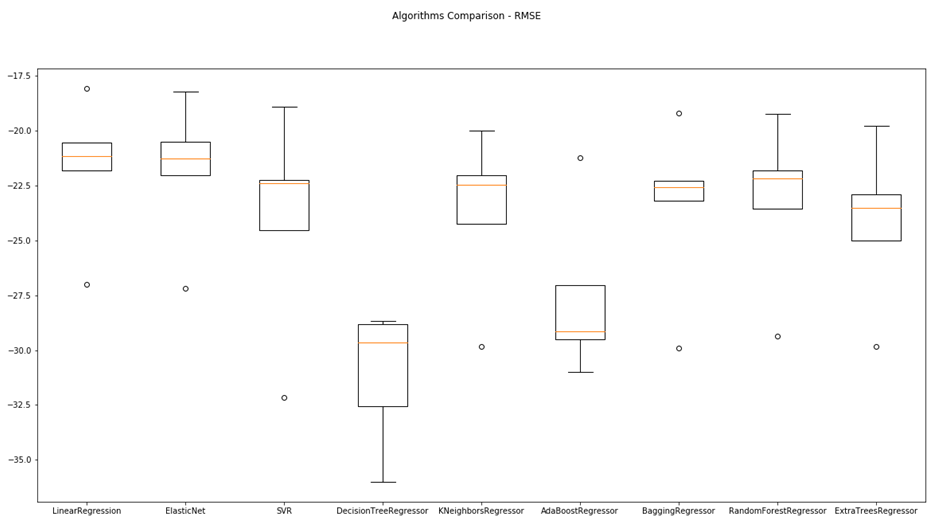
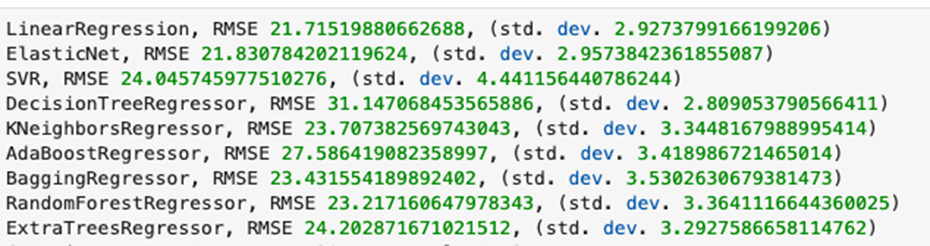
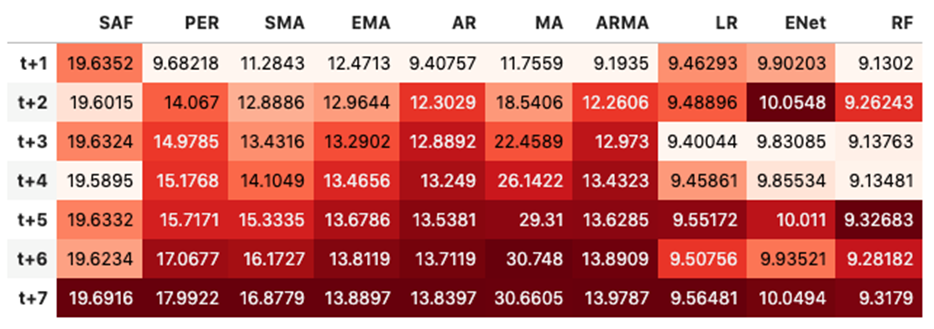
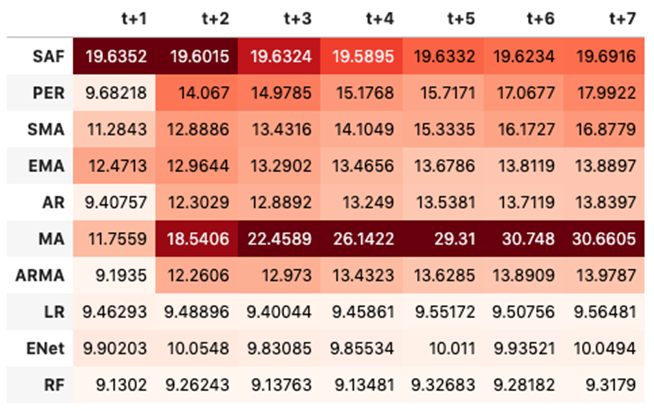
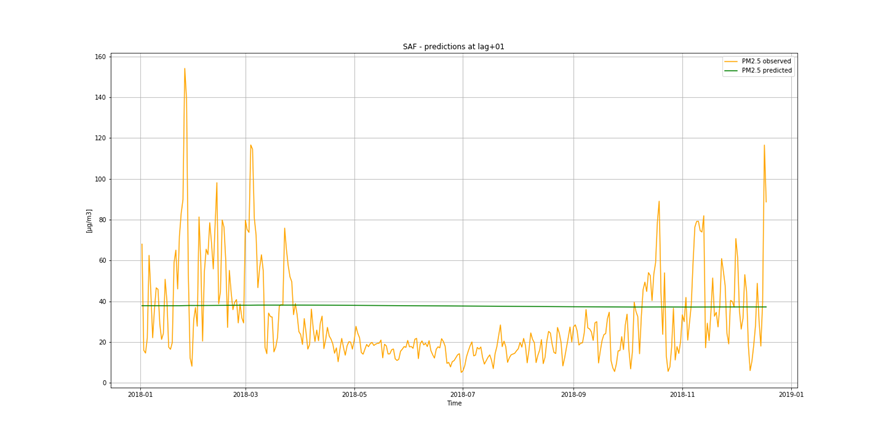
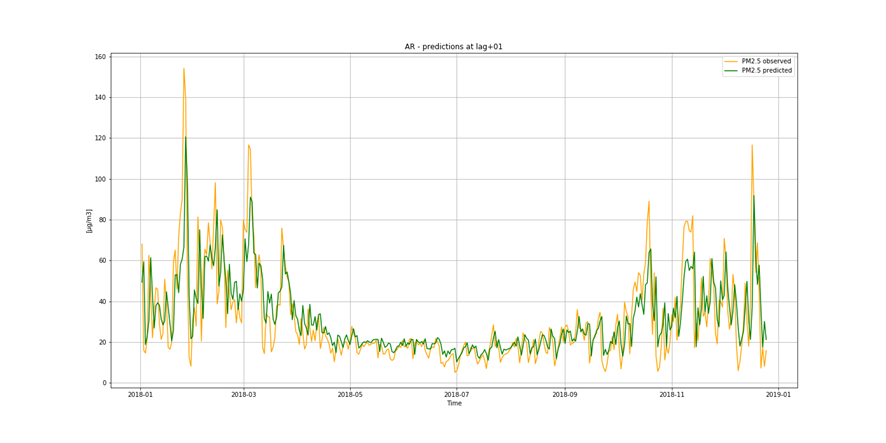
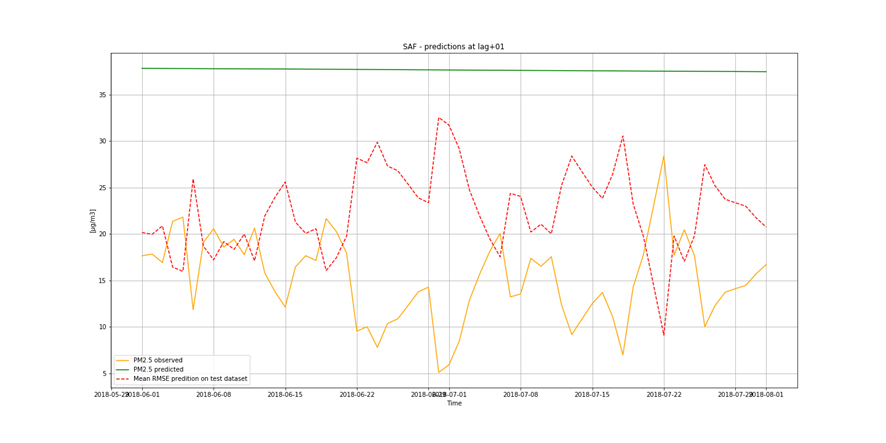
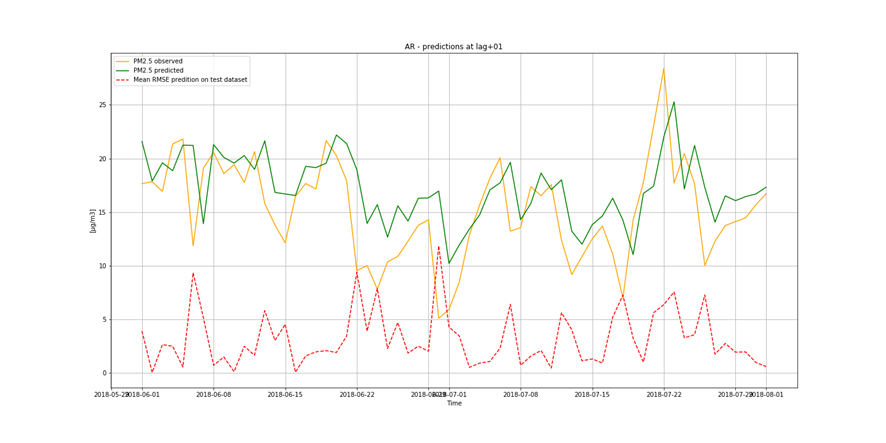
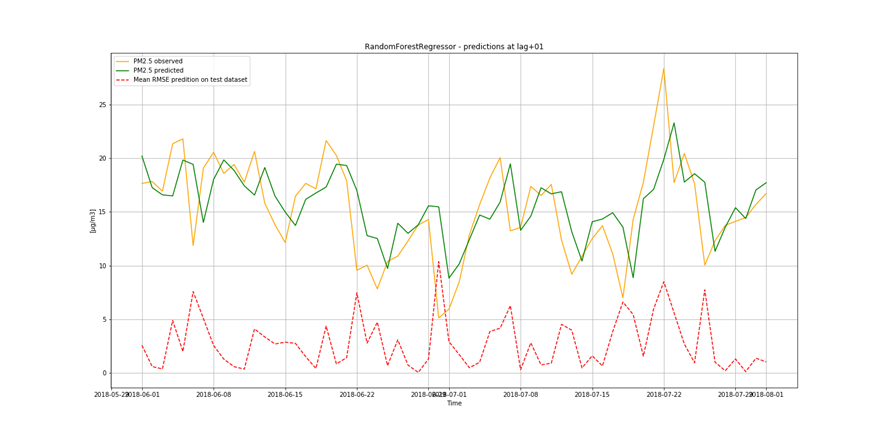
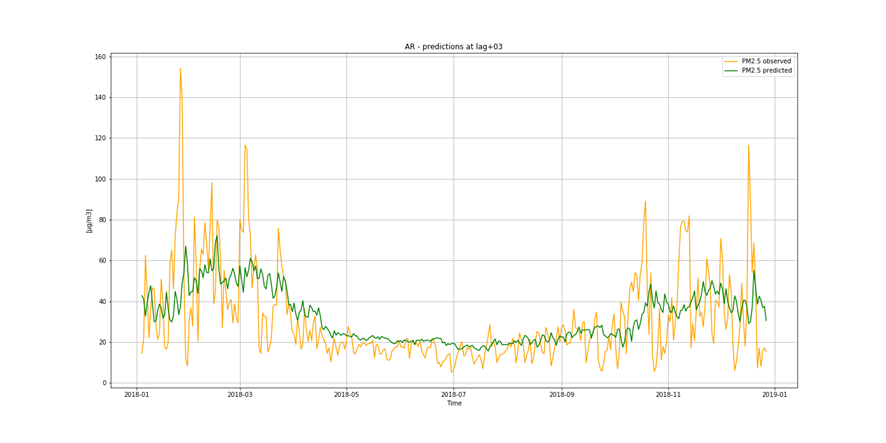
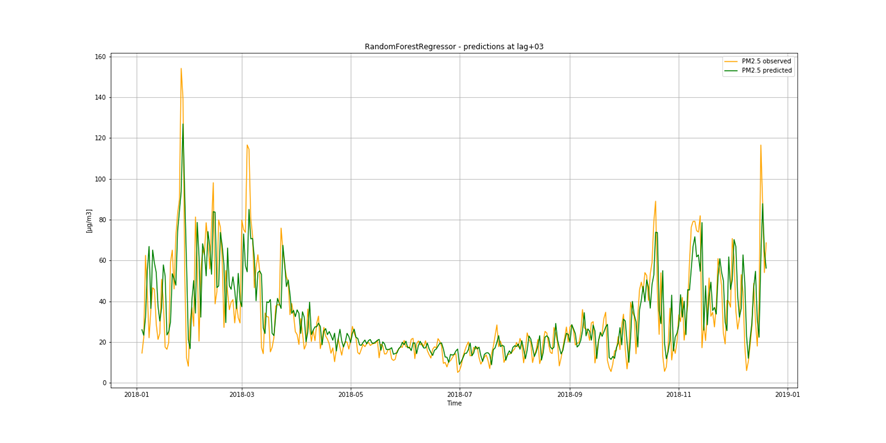
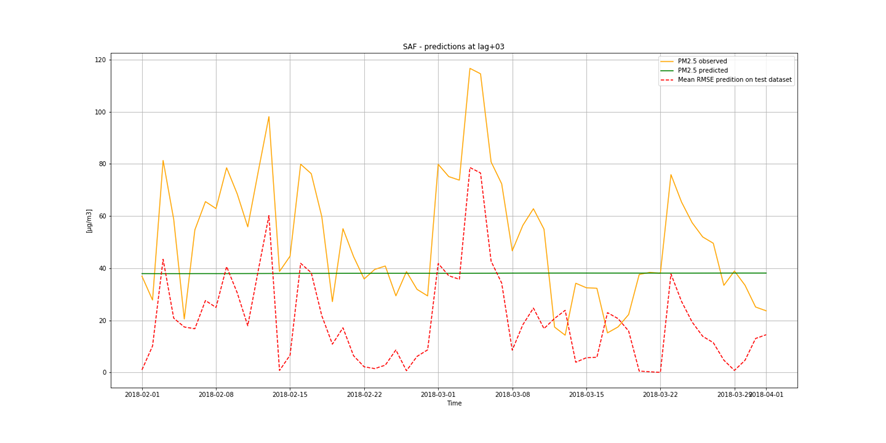
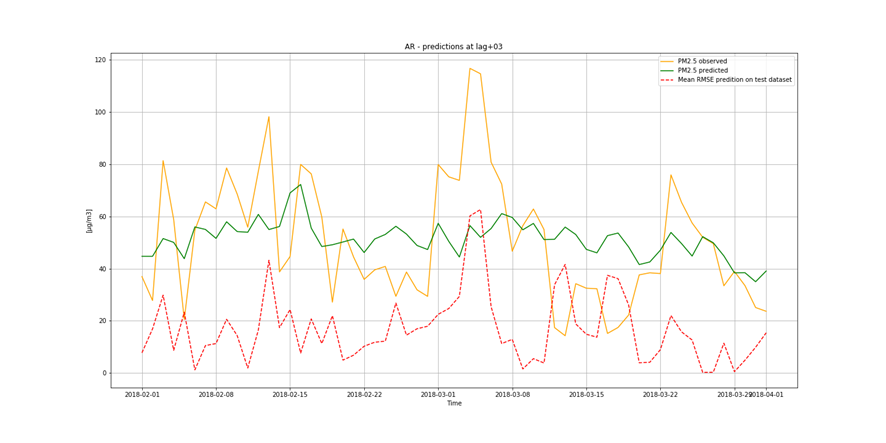
It is important to find best analytical methods for predicting fine particles of particulate matter (PM2.5) level. This could help ordinary people in planning any activities in the open air and reduce impact the air pollution makes to their health.